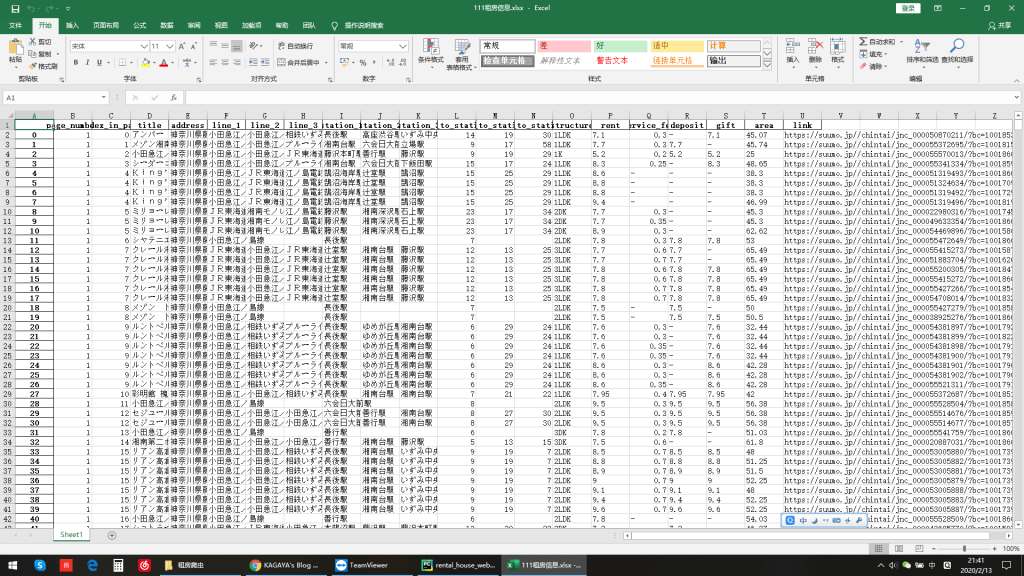
前回より、大雑把なエリアを決定し、今回はSUUMOからの物件をスクレイピングします。目的地は藤沢周辺です。
最初に総ページ数を見つけます:
number_of_pages = bs.find('ol', {'class': 'pagination-parts'}).find_all('li')[-1].find('a').get_text() # 找出租房物件总页数
そして、一ページの情報採集、ループに入れて、出力します。
一個一個のページが終わったら、excelに更新して出力します。万が一ネット通信エラーとか、サバーに禁止されるとかの際に、取った情報を確保します。
余計な情報を略すため、藤沢と辻堂いずれかの情報があれば、別のファイル保存します。(Boolマスクを作る)
# 选出必定在藤泽和辻堂駅附近的房屋
new_df = df[(df['station_1'] == '藤沢駅') | (df['station_1'] == '辻堂駅') | (df['station_2'] == '藤沢駅') | (
df['station_2'] == '辻堂駅') | (df['station_3'] == '藤沢駅') | (df['station_3'] == '辻堂駅')]
Entire code:
# -*- coding: utf-8 -*
import urllib.request
import random
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import math
import time
import pandas as pd
import numpy as np
MAIN_URL = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=14&sc=14205&cb=0.0&ct=9999999&et=9999999&cn=9999999&mb=0&mt=9999999&tc=0400901&shkr1=03&shkr2=03&shkr3=03&shkr4=03&fw2=&page=' #
INFORMATION_DIC = {}
INFORMATION_DF = pd.DataFrame({'page_number': [], 'index_in_page': [], 'title': [],
'address': [], 'line_1': [], 'line_2': [], 'line_3': [], 'station_1': [],
'station_2': [], 'station_3': [], 'time_to_station_1': [], 'time_to_station_2': [],
'time_to_station_3': [], 'structure': [], 'rent': [], 'service_fee': [],
'deposit': [], 'gift': [], 'area': [], 'link': []}, index=None)
def span_over_pages(object_url, total_pages): # 对原始链接的所有页数爬虫
for i_page_number in range(1, total_pages + 1):
executed_url = ''.join([object_url, str(i_page_number)])
try:
execute_web_scrape(executed_url, i_page_number)
except Exception as e:
print('error!')
raise
else:
INFORMATION_DF.to_excel('租房信息.xlsx')
# print(df)
print('Page ', i_page_number, 'done.')
time.sleep(3)
def execute_web_scrape(executed_url, page_number): # 对当前页面进行爬取
global START_LOG
bs_item_boxes = BeautifulSoup(urlopen(executed_url).read(), 'html.parser').find_all('div',
{'class': 'cassetteitem_content'}) # 所有项目框
bs_agent_boxes = BeautifulSoup(urlopen(executed_url).read(), 'html.parser').find_all('table', {'class': 'cassetteitem_other'}) # 所有中介框
INFORMATION_DIC[page_number] = {}
for item_index_in_page in range(len(bs_item_boxes)): # 遍历每一条目
print('item {0} collected:\n'.format(item_index_in_page))
# 定位所有物件信息块
building_configs = bs_agent_boxes[item_index_in_page].find_all('tr', {'class': 'js-cassette_link'})
# 得到同栋楼物件信息块
room_information_blocks = [building_configs[i].find_all('li') for i in range(len(building_configs))]
house_address = bs_item_boxes[item_index_in_page].find_all('li', {'class': 'cassetteitem_detail-col1'})[
0].get_text() # 住所地址
add_bs = bs_item_boxes[item_index_in_page].find_all('div', {'class': 'cassetteitem_detail-text'}) # 通勤情况
commuting_list = [add_bs[i].get_text() for i in range(len(add_bs))] # 把通勤情况所有记录在列表里
INFORMATION_DIC[page_number][item_index_in_page] = {}
INFORMATION_DIC[page_number][item_index_in_page]['title'] = \
bs_item_boxes[item_index_in_page].find_all('div', {'class': 'cassetteitem_content-title'})[0].get_text()
INFORMATION_DIC[page_number][item_index_in_page]['add'] = commuting_list
house_name = bs_item_boxes[item_index_in_page].find_all('div', {'class': 'cassetteitem_content-title'})[
0].get_text() # 找出物件名称
route_list = list(filter(None, commuting_list)) # 去除空信息, 对象变list, 并去除/
line_used = [re.search(r'.+(\/)', route_list[i]).group().rstrip('/') for i in range(len(route_list))]
station_used = [re.search(r'(\/)[^\s]+', route_list[i]).group().lstrip('/') for i in range(len(route_list))]
time_to_station_phrase = [re.search(r'(\s).{1,2}(\d)+.', route_list[i]).group() for i in range(len(route_list))]
# time_to_station_phrase = [re.search(r'(\s).+', route_list[i]).group() for i in range(len(route_list))]
# 得到移动时间列表
time_to_station_phrase_splited = [re.split('(\d+)', time_to_station_phrase[i]) for i in range(len(route_list))]
time_to_stations = np.full(3, np.nan) # 用nan占位
lines = [np.nan, np.nan, np.nan]
stations = [np.nan, np.nan, np.nan]
for each_approach in range(len(time_to_station_phrase_splited)): # 赋真实值
# 得到移动时间
time_to_stations[each_approach] = time_to_station_phrase_splited[each_approach][1]
# 得到乘坐线路
lines[each_approach] = line_used[each_approach]
# 得到乘坐站点
stations[each_approach] = station_used[each_approach]
# 添加该租房项目记录
for i in range(len(room_information_blocks)):
rent = re.search(r'(\d)+(\.){0,1}(\d)*', room_information_blocks[i][0].get_text()).group()
service_fee = lambda x: x if len(x) == 1 else float(re.search(r'(\d)+(\.){0,1}(\d)*', x).group()) / 10000
deposit = lambda x: x if len(x) == 1 else re.search(r'(\d)+(\.){0,1}(\d)*', x).group()
gift = lambda x: x if len(x) == 1 else re.search(r'(\d)+(\.){0,1}(\d)*', x).group()
structure = room_information_blocks[i][4].get_text()
area = re.search(r'(\d)+(\.){0,1}(\d)*', room_information_blocks[i][5].get_text()).group()
inter_link = building_configs[i].find('td', {'class': 'ui-text--midium ui-text--bold'}).find('a', {
'class': 'js-cassette_link_href cassetteitem_other-linktext'}).attrs['href']
INFORMATION_DF.loc[START_LOG] = [page_number, item_index_in_page, house_name,
house_address, lines[0], lines[1], lines[2],
stations[0], stations[1], stations[2],
time_to_stations[0],
time_to_stations[1], time_to_stations[2],
structure, rent,
service_fee(room_information_blocks[i][1].get_text()),
deposit(room_information_blocks[i][2].get_text()),
gift(room_information_blocks[i][3].get_text()), area,
''.join(['https://suumo.jp/', inter_link])]
START_LOG = 1 + START_LOG
# print('dic is: \n', INFORMATION_DIC)
if __name__ == '__main__':
START_LOG = 0
bs = BeautifulSoup(urlopen(''.join([MAIN_URL, str(1)])).read(), 'html.parser')
number_of_pages = bs.find('ol', {'class': 'pagination-parts'}).find_all('li')[-1].find('a').get_text() # 找出租房物件总页数
print('number_of_pages is: ', number_of_pages)
span_over_pages(MAIN_URL, int(number_of_pages))
df = pd.read_excel('租房信息.xlsx', index=None)
# 选出必定在藤泽和辻堂駅附近的房屋
new_df = df[(df['station_1'] == '藤沢駅') | (df['station_1'] == '辻堂駅') | (df['station_2'] == '藤沢駅') | (
df['station_2'] == '辻堂駅') | (df['station_3'] == '藤沢駅') | (df['station_3'] == '辻堂駅')]
new_df.to_excel('rental_information.xlsx', index=None)