# -*- coding: UTF-8 -*-
from sklearn.datasets import fetch_species_distributions
from mpl_toolkits.basemap import Basemap
from sklearn.datasets.species_distributions import construct_grids
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KernelDensity
data = fetch_species_distributions()
# 获取物种ID和位置矩阵、数组
latlon = np.vstack([data.train['dd lat'], data.train['dd long']]).T
print('latlon.shape: ', latlon.shape)
# .startswith('micro')检查字符串是否是以micro字符串开头, 返回布尔数组
species = np.array([d.decode('ascii').startswith('micro') for d in data.train['species']], dtype='int')
print('species.shape: ', species.shape)
xgrid, ygrid = construct_grids(data) # 创建格子,供形成地理图的坐标用
m = Basemap(projection='cyl', resolution='c', llcrnrlat=ygrid.min(), urcrnrlat=ygrid.max(),
llcrnrlon=xgrid.min(), urcrnrlon=xgrid.max())
m.drawmapboundary(fill_color='#DDEEFF')
m.fillcontinents(color='#FFEEDD')
m.drawcoastlines(color='gray', zorder=2)
m.drawcountries(color='gray', zorder=2)
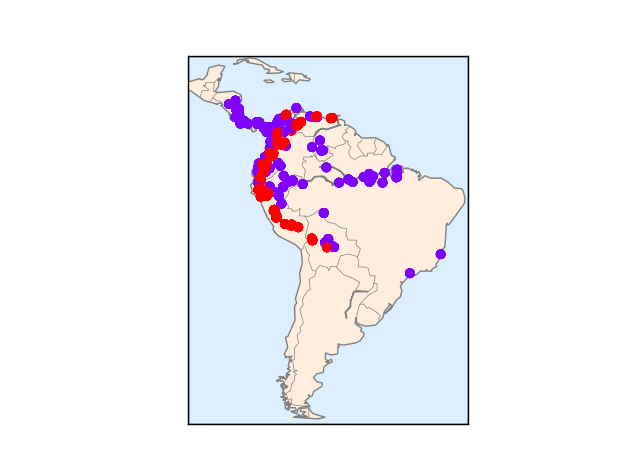
m.scatter(latlon[:, 1], latlon[:, 0], zorder=3, c=species, cmap='rainbow', latlon=True)
# 用核密度估计对分布点进行概率分布(平滑化)
# 画轮廓图的数据点
X, Y = np.meshgrid(xgrid[::5], ygrid[::5][::-1]) # 每五个挑出(减小机器负担),ygrid最后还要倒序
# http://wiki.swarma.net/index.php?title=%E9%A2%84%E6%B5%8B%E7%89%A9%E7%A7%8D%E7%9A%84%E7%A9%BA%E9%97%B4%E5%88%86%E5%B8%83&variant=zh-mo
land_reference = data.coverages[6][::5, ::5] # [6]代表用四月降水量信息来得到陆地信息(因为有情报的都是陆地),每五个挑出(减小机器负担)
land_mask = (land_reference > -9999).ravel() # 矩阵中的缺失数据用-9999来表示(是海洋), 形成非缺失值的mask,即为陆地mask
xy = np.vstack([Y.ravel(), X.ravel()]).T
xy = np.radians(xy[land_mask]) # xy需要显示的行数被[land_mask]挑出来,度转换为弧
fig, ax = plt.subplots(1, 2)
fig.subplots_adjust(left=0.05, right=0.95, wspace=0.05)
species_names = ['Bradypus Variegatus', 'Microryzomys Minutus']
cmaps = ['Purples', 'Reds']
for i, axi in enumerate(ax):
axi.set_title(species_names[i])
# 画地理图
m = Basemap(projection='cyl', llcrnrlat=Y.min(), urcrnrlat=Y.max(), llcrnrlon=X.min(), urcrnrlon=X.max(),
resolution='c', ax=axi)
m.drawmapboundary(fill_color='#DDEEFF')
m.drawcoastlines()
m.drawcountries()
# 构建球形分布核密度估计
kde = KernelDensity(bandwidth=0.03, metric='haversine') # 'haversine'衡量球面距离
kde.fit(np.radians(latlon[species == i])) # 获取各种类的地理位置信息,化为弧度值,埋入模型
# 计算大陆值,-9999是海洋
Z = np.full(land_mask.shape[0], -9999.0) # np.full()生成land_mask.shape[0]形状,-9999的数组
Z[land_mask] = np.exp(kde.score_samples(xy)) # score_samples()返回概率密度对数值,只计算陆地的,xy是陆地弧度值坐标
Z = Z.reshape(X.shape) # 化为X形状供显示
# 画出密度轮廓
levels = np.linspace(0, Z.max(), 25) # Z.max()是最大密度估计
# 输入的参数是x,y对应的网格数据以及此网格对应的高度值levels,之前先要调用np.meshgrid(x,y)把x,y值转换成网格数据
axi.contourf(X, Y, Z, levels=levels, cmap=cmaps[i])
plt.show()